Welcome to Émile Mâle Pipeline
This project is developed by Parth Shukla for Google Summer of Code 2022 with Red Hen Lab.
API developed using the work done in GSoC’22 can be found here.
To anyone interested in approaching me to clear things, feel free to contact me on parthshukla285@gmail.com
Project Description
- A knowledge extraction pipeline for artworks from christian iconography that will be used to create a knowledge graph for Christian Iconography. The intention of knowledge graph is that it should help untutored eyes find connections between different artworks. This project is divided into 4 main parts: 1) A model to find the parts of the image that might be useful to us and extract those regions of interest 2) A classification model that would extract possible classes as well as items and use the confidence scores 3) Defining an ontology that would be the skeleton for our knowledge graph. It would be able to tackle the problem of finding connections between separate artworks using the confidence scores found in the previous step 4) Finally, we would populate our knowledge base with the help of our ontology.
Quick Index of Daily Progress
Community Bonding Period
- Blog Report 1 (May 20 - Jun 12)
Coding Period
- Blog Report 2 (Jun 13 - Jun 19)
- Blog Report 3 (Jun 20 - Jun 26)
- Blog Report 4 (Jun 27 - Jul 3)
- Blog Report 5 (Jul 4 - Jul 10)
- Blog Report 6 (Jul 11 - Jul 17)
- Blog Report 7 (Jul 18 - Jul 24)
- Progress Check
- Blog Report 8 (Jul 25 - Jul 31)
- Blog Report 9 (Aug 1 - Aug 7)
- Blog Report 10 (Aug 8 - Aug 14)
- Blog Report 11 (Aug 15 - Aug 21)
- Blog Report 12 (Aug 22 - Aug 28)
- Blog Report 13 (Aug 29 - Sep 4)
- Blog Report 14 (Sep 5 - Sep 12)
Future work
Community Bonding Period
Preparation Stage
- May 23: Finish blog and profile set-up
- Jun 1: CWRU HPC set-up
- Jun 3: Inital understanding on Singularity and running a trial singularity on HPC
- Jun 8: Meet and Greet with Red Hen Lab Mentors and GSoC participants
Blog Report 1
Part 1: Completed preparation tasks
The following small tasks have been completed by Jun 12, Sunday.
- Understand Red Hen Techne Public Site
- Understand how to create Singularity and other information related to Singularity
- Connected with Rishab, who has a project in the same domain.
- Learnt about Class Activation Maps(Link to get you started - https://towardsdatascience.com/class-activation-mapping-using-transfer-learning-of-resnet50-e8ca7cfd657e)
- Reading of Comparing CAM Algorithms for the Identification of Salient Image Features in Iconography Artwork Analysis by Nicolò Oreste Pinciroli Vago,Federico Milani, Piero Fraternali and Ricardo da Silva Torres.
- Reading of A Dataset and a Convolutional Model for Iconography Classification in Paintings which presented a huge dataset on Christian Iconography.
- Preliminary study of Christian Iconography with focus on the saints presented in the ArtDL dataset. Studying what icons are specific to what saints and if there are common elements to different saints. See Christian Iconography. For example, Antony Abbot usually has a bell, Saint Peter has 2 keys in his hand. There are also common icons like Lily is representative of Mother Mary as well as Dominic. Similarly, Sword is common for Barbara and Catherine.
Study materials
My study materials and important websites that may be helpful for other student who takes over this project:
Coding Period
Blog Report 2
- Coding Period begins
Before the official coding period, I mainly finished the following preparation works.
- Gain a basic understanding of the ArtDL dataset and its classes
- Gain a basic understanding of the Christian Iconography
- Understanding Class Activation Maps and how they work
- Decide on CAM algorithm to pursue
- Literature reading
Some thoughts:
What, Why and How of the project
What
The purpose of this project is to come up with a pipeline which could imitate Émile Mâle and act as a learning tool which could help the a beginner just dipping their toes in the ocean of Christian Iconography.
Why
The importance of this pipeline is that it would make Christian Iconography accessible to people who do not have formal education in this field. Especially useful to high-school or college students who do not have a master in this subject guiding them. In the great ocean of Christian Iconography, art pieces are isolated and disconnected, however that is not the intention of the artist. Art is meant to inspired from other pieces of art. I hope to find a way to show that connection in a computational manner.
How
Below, is a high-level Data flow diagonal defining the steps to solve the problem.
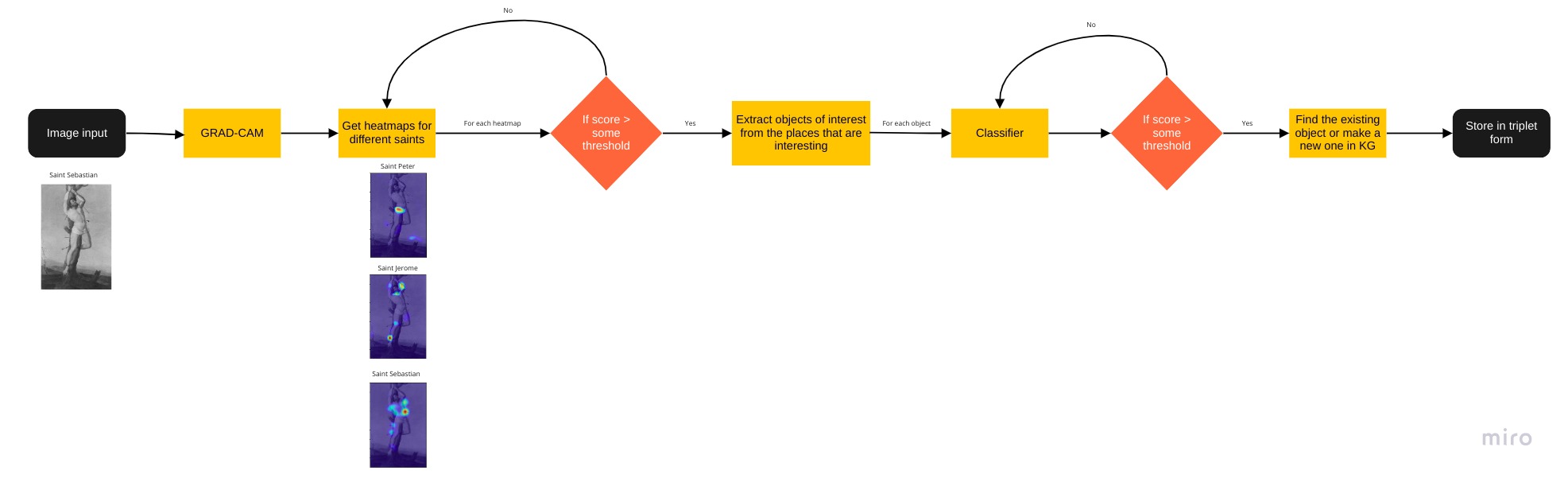
Implementation:
I found an extremely useful article to understand GRAD-CAM. In order to get good results for our CAM methods we need to train our model on a tagged dataset. Luckily, we have a good dataset prepared by Federico Milani and Piero Fraternalli called the ArtDL. It is available on http://www.artdl.org/. I will use this dataset to train my model. Class Activation Maps(CAM) are extremely useful in helping us understand how a model learns features to distinguish between different classes just as our brain does i.e it observes patterns. Prior to CAM methods, deep learning models were broadly considered to be black boxes and we had to accept the results given by it without understanding what was going on under the hood.
The expected output from this module are bunch of heatmaps for all the classes which have a positive prediction score. Then using these heatmaps, we want to retrieve these objects of interest. This can be done in a way similar to the one explained in https://www.mdpi.com/2313-433X/7/7/106/htm
The candidate region proposals to use as automatic bounding boxes have been identified with the following heuristic procedure.
- Collect the images on which all the four methods satisfy a minimum quality criterion: for symbol bounding boxes component IoU greater than 0.165 at threshold 0.1 and for whole Saint bounding boxes global IoU greater than 0.24 at threshold 0.05;
- Compute the Grad-CAM class activation map of the selected images and apply the corresponding threshold: 0.1 for symbol bounding boxes and 0.05 for whole Saint bounding boxes;
- Only for symbol boxes: split the class activation maps into connected components. Remove the components whose average activation value is less than half of the average activation value of all components. This step filters out all the foreground pixels with low activation that usually correspond to irrelevant areas;
- For each Iconclass category, draw one bounding box surrounding each component (symbol bounding boxes) and one bounding box surrounding the entire class activation map (whole Saint bounding boxes).
Even though the method mentioned above is not exactly applicable to my use-case, for example- we do not have ground truth dataset for bounding boxes so we can not use the IoU metric, however it does help me to get an idea about how to go ahead. I recommend checking the Github repository for all the notebooks.
ResNet50 architecture:
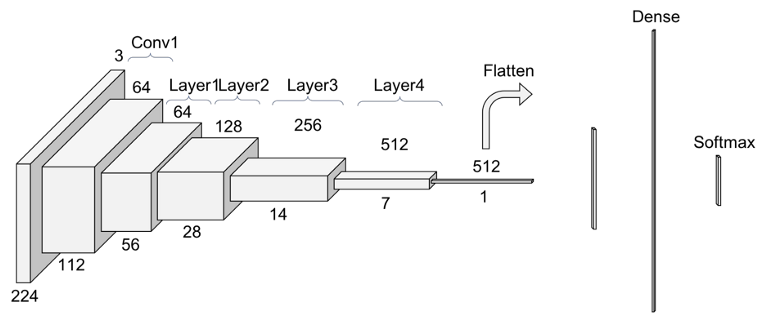
If you background information on ResNet, I recommend going through this article.
Output of layer 3 gives us a 14x14 matrix whereas layer 4 gives us a 7x7. These matrices are then expanded to 224x224 which is superimposed on the original image to visualise output. An observation was that layer 3 would give more number of regions because there are more discontinuous regions whereas layer 4 being smaller would give lesser number of outputs.
Blog Report 3
Goals for this week:
- Utilise HPC to train models
- Complete the module which can crop out and extract the regions of interest produced by Grad-CAM for different classes
HPC is something completely new to me. HPC provides us with a tremendous amount of computatinal power and it is important to properly undrstand the capabilities of it while also understanding that it is a shared space and you should not cause any inconvenience to fellow participants. I spent sometime reading up on the techne site to better understand how to schedule tasks. There are two ways to access GPUs i.e interactive job and batch job. I was more comfortable using the batch job. To submit batch jobs you need to submit slurm scripts. I have uploaded my slurm scripts in my repository for anyone stuck in the same position as me. Getting my jobs running on the cluster took some time and I was stuck on it for a few days. Thanks to Dr. Peter Uhrig I was able to figure it out on a scheduled call. After that, I trained my model on the cluster.
Object extractor
If I cosider the results after the layer 3 of ResNet50, I get the following 14x14 matrix(truncated image)

I need to find the connected regions in this matrix. This can be easily solved by applying Depth First Search, similar to “Count the number of island”. I also applied a criteria that a cell could only be considered valid if its value was greater than the median of the entire matrix. This would help to ignore foreground pixels.
Intermediate output looks like

After getting this, we just need to bound an “island” in a box. For example, the island 2 would be bounded by a rectangle covering the columns 2–4 in row 1.
Coordinates for these boxes, once we get, can be easily extrapolated to get the exact pixel location for the object of interest in the image.
For example, Let’s take an example of Mary

Output of the module for Mary

Blog Report 4
Goals for this week
- Putting all of the work done till now together
- Research on EfficientNet as a method for the second module
I compiled all the code and put it al together so that I could run it on the cluster and get the results back on my computer to observe. The data used for this part was test data i.e data previously unseen by the model.
Difficulties
- Storing the meta-data for the extracted objects.
- Nomenclature of the extracted images should be consistent as the they are huge in number(for example, can have 170 regions of interest for all the classes combined, if not more, now considering only the test dataset which is roughly 4000 pieces of art, we could be dealing with storing 170*4000=680,000 images).
- Not all of these 680,000 images are useful entities, there is a possibility that it may only contain background pixels not representing anything of substance. This problem would be tackled in the next part of our pipeline.
- The huge amount of images being produced were difficult to work with.
Solutions
- I stored the metadata in this format for now
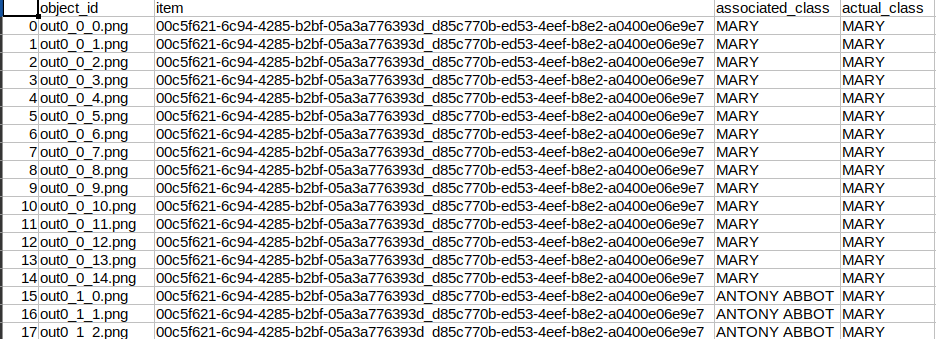
Columns - object_id, item(basically Image name, consistent with ArtDL), associated_class(which is the class for which the object was generated) and actual_class(which is the class it belongs to according to ArtDL).
- One method to reduce number of images was if I took output for layer 4 instead of layer 3 of my ResNet50 model as it would privide a 7x7 matrix.
So where are we now?

And this is how images look like
In order to make sense of these extracted images, I wanted to train a classifier on a dataset of images of some popular symbols of iconography eg, Baby(for baby jesus),Book,Key,Flowers,Cross,Ointment jar,Arrow,Bird,Sword,Dog. I tried EfficientNet architecture to do so, here is the notebook for it. However, the results were not promising on the extracted objects. My theory behind why it might not be performing well: 1) Training data was not translating well to the testing data maybe because the testing data was way more than training data 2) Curated dataset on which the model was trained was not good enough 3) Testing data may be too dissimilar to training data.
Meeting
Sharing my result and progress on the call, I was adviced to try to focus on Mother Mary and see how the results are. Build in a modular way so that it is possible to expand the pipeline going forward. This change makes sense as well since the dataset I am using has around 60% examples of Mary.
So based on this I modified my approach a little.
Blog Report 5
Goals
- Modify pipeline to accomodate the change mentioned above
- Re-training ResNet50 from the first module
- Getting the extracted objects similar to the outputs you see above but with the new model only for MARY
My modified pipeline looked something like this
.jpg)
The main change from the previous approach is that, the system first tries to decide if art is of Mary
- If it is Mary, extracts the object using CAM and stores its instance
- If it is not Mary, extracts objects using CAM for Mary and stores its instance
But why do we need this change?
Let’s say we have an image tagged with the label St. Sebastian. However, when the artist was painting this, they were told to also include a Pear in the painting. Pear is an important symbol for Mother Mary as it shows the sweetness of her soul. Artist included this to give associate Mother Mary to the scene depicted in the painting.
Our first module will be able to classify this image as OTHER i.e not related to Mary, however there still are elements to Mary in this, for example the Pear. When we pass this image through our first module. We get the output of a cropped image of the pear with the metadata saying that the pear represents Mother Mary. This information will then need to be ingested into our Knowledge Graph.
Implementation
To implement this, I had to change the way I was passing the training data to model. If the image was of Mary, I was passing the label 0 and if it was any other saint then I would pass the label 1. Training ResNet50 for only a few epochs I was able to achieve ~81 percent testing accuracy. In additon to these changes, I also freeze first two blocks of ResNet50 which showed an increase in performance.
For getting the output this time, I decided to utilise the layer 4 of ResNet because of the reason I mentioned a few pages up, the amount of outputs I got from layer 3 were huge and inpossible to observe and were redundant too.
The metadata file for outputs looks like this

Explanation - First row has the object_id out0_0_0.png, this means it is output of first image in the testing dataset and the current label for it 0(MARY) and it is the first object extracted in this image.
First number - index number in the testing dataset
Second Number - Class number i.e 0 for MARY and 1 for OTHER
Third Number - Counter for number of instances produced for that particular image and class
Blog Report 6
Goals
- Find methods to create embeddings using Iconography texts
Monday
Further reading of material on Mary and making a note of her symbols like Crown, Lilies, Mystic [or Mystical] Rose, Iris, Pear, Fleur-de-lys(?), Baby Jesus, Rosary, Stars(from crown of stars), Blue robe, Crescent - because of immaculate conception, Granada. Collected a few images on these items and ran EfficientNet.
- Mentor meeting
Continued discussion of the scope of the project with Prof. Mark Turner and Tiago Torrent. Format of blog was also discussed. Tiago mentioned some ideas using the large corpora of christian iconography texts available. Some possibilities like texts can be used to generate a domain for christian iconography, also examples of how caption generation techniques can be used to help image tagging.
- Ideas after the meeting
- See how to utilise textual data to create embeddings
- Look into auxillary learning
- Find previous relevant computer vision work in Iconclass for indicators
- Problems I’m still not sure how to solve How to use Computer Vision for these images to utilise the embeddings. Maybe use YOLOv6 on images and then each instance can become a relationship between the two objects and then the embeddings can help me in tagging the image.
Tuesday
- Restructuring the blog similar to the style followed by Wenyue Xi (Suzie) for Google Summer of Code 2020 for their project. Reason - previously I was only blogging results and decisions, however it is also important to document all the challenges faced in the process because other people will certainly face difficulties and this would help them understand how my project progressed and why I did certain things and how they could build on it and don’t struggle on the same step.
- Read up on Auxillary Learning. Highly recommend going through this article for it.
Wednesday
Looking into ways to create embeddings. According to wiki, Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. One of the most common example for learning embeddings are word2vec. I have worked with word2vec before, mostly using GloVe, however I have never learnt embeddings from scratch. There is a good article on it.
Results:
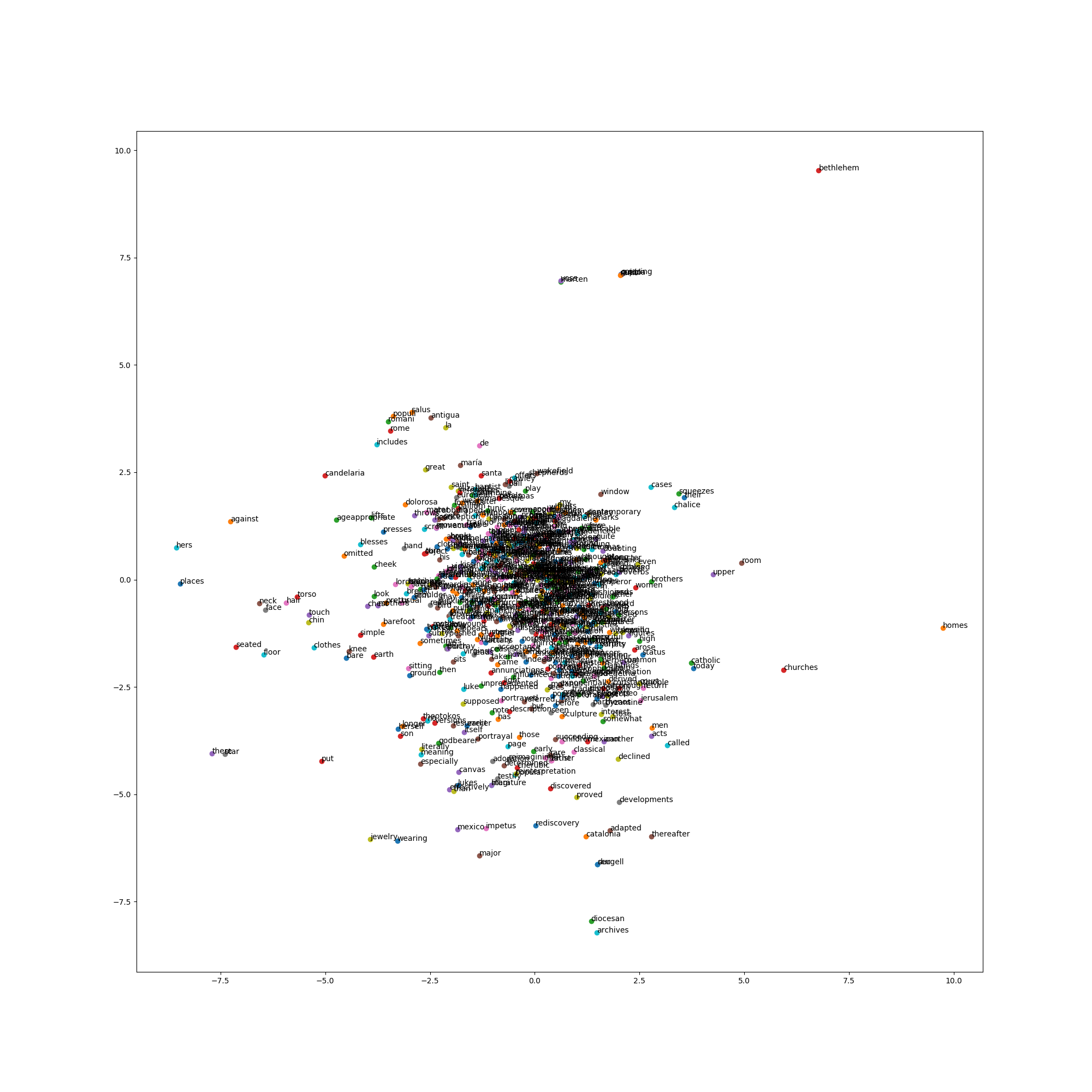
Words in close association to Mary

There is more scope to this method because we can see ‘lorenzettis’ who is a painter, ‘crucifixion’, ‘heaven’ and ‘child’ in closeness to Mary but there is more need for data cleaning and selecting the right type texts so that more relevant symbols can be close to Mary.
Thursday
- Learnt further about embeddings. link
- Another great article on Word2Vec.
- Towards Generating and Evaluating Iconographic Image Captions of Artworks
- Multi-modal Label Retrieval for the Visual Arts: The Case of Iconclass
- Iconclass image captioning
In order to leverage Word2Vec embeddings, I have come up with a possible solution that could help us confirm our tags and also change tags if confident enough. It is based on something Tiago Torrent mentioned on the class where we can utilise textual data to create embeddings and those embeddings help us tag image or even correct images. These methods are very popular incaption generation tasks.
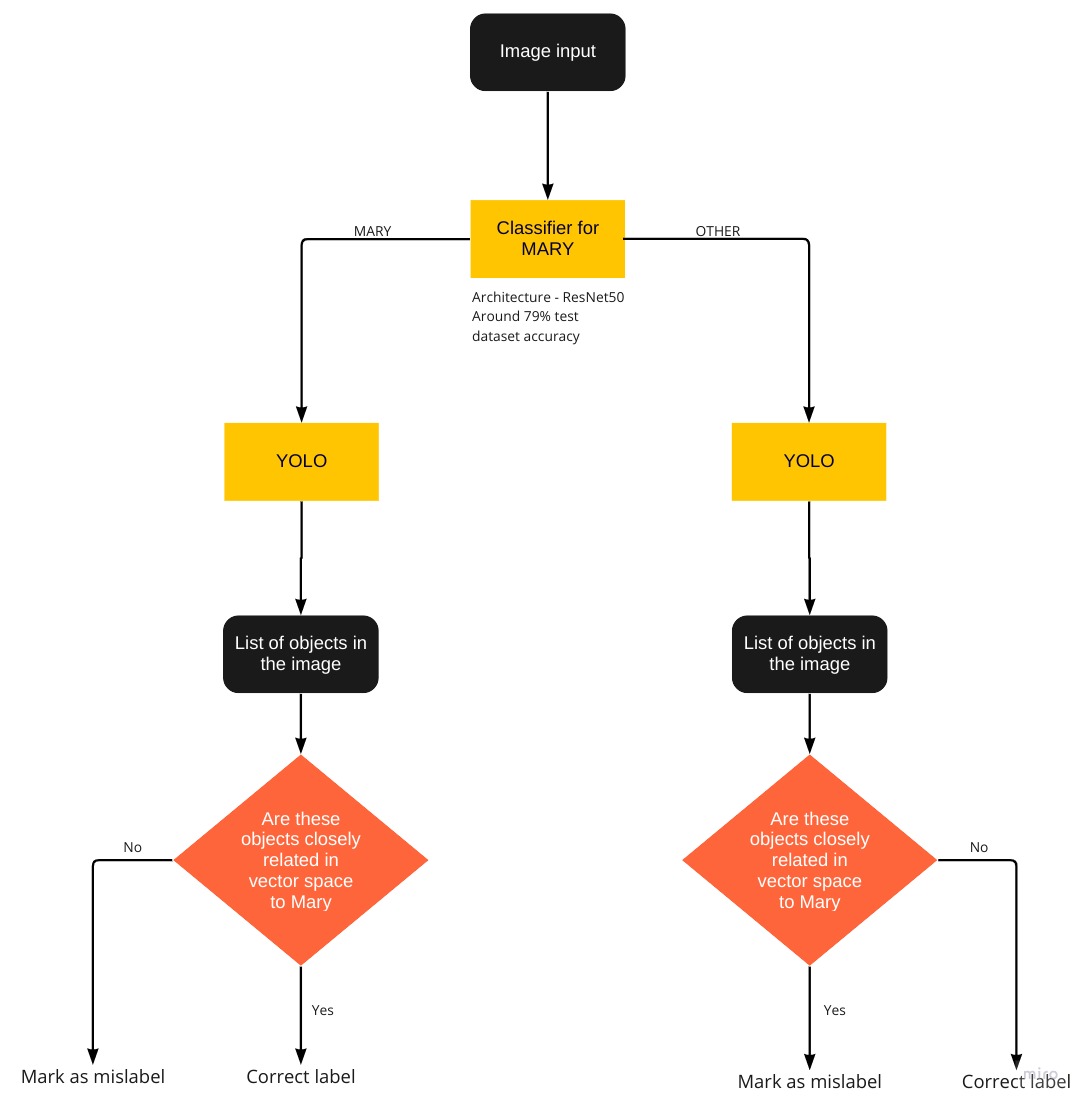
The “Mark as mislabel” in the classifier can be used to change the label as well if the confidence score received by using the embeddings are confident enough.
Problems in this technique:
- The embeddings need to be more representative, this would require more cleaning of textual data and also adding more sources. I am looking into this.
- There are no datasets or models that can generalise well enough for the task which is to be done by YOLO. I will have manually define what symbols to target and tag some current artworks to train YOLO.
Friday
- Learnt about YOLO
- Plan on how to utilise captions from here using Iconclass AI test set. Iconclass AI test set has a json file which contains image filenames with associated Iconclass categorisation. For now, since our scope is limited to MARY we can utilise all the filenames with classes starting with “11F” and search for their captions on the github repo.
- Discussion with Rishab on how to integrate our projects.
- Try different texts for Word2Vec.
Blog Report 7
Goals-
- Create embeddings and utilise them
- Train YOLO on a dataset with annotations for Christian Iconoraphy. This process would would require me to curate a dataset and annotate them and followed by training.
Monday
- Tried training Word2Vec on HPC, however ran into trouble relatin to versioning so will continue trying to fix that.
- Began the process of curating a dataset for training YOLO. Tagged a hundred images belonging to Mary with objects such as baby, person, angel, book, jar, crown etc. In a lot of the images, we have mary depicted as a maiden with a baby on lap or on her arms. However, some of the artwork really stands out in their potrayal of Mary.
Current version of the dataset: link
Some generalizations I have made during tagging: It is tough to distinuguish between halo and a crown and both of them rest at the top of the head, so I have tagged them under the same label. Jar - Jar is for ointment jar which is common for Mary Magdalene, but still appears in Mother Mary so I have tagged them and moving forward we can see if they turn out to be useful.
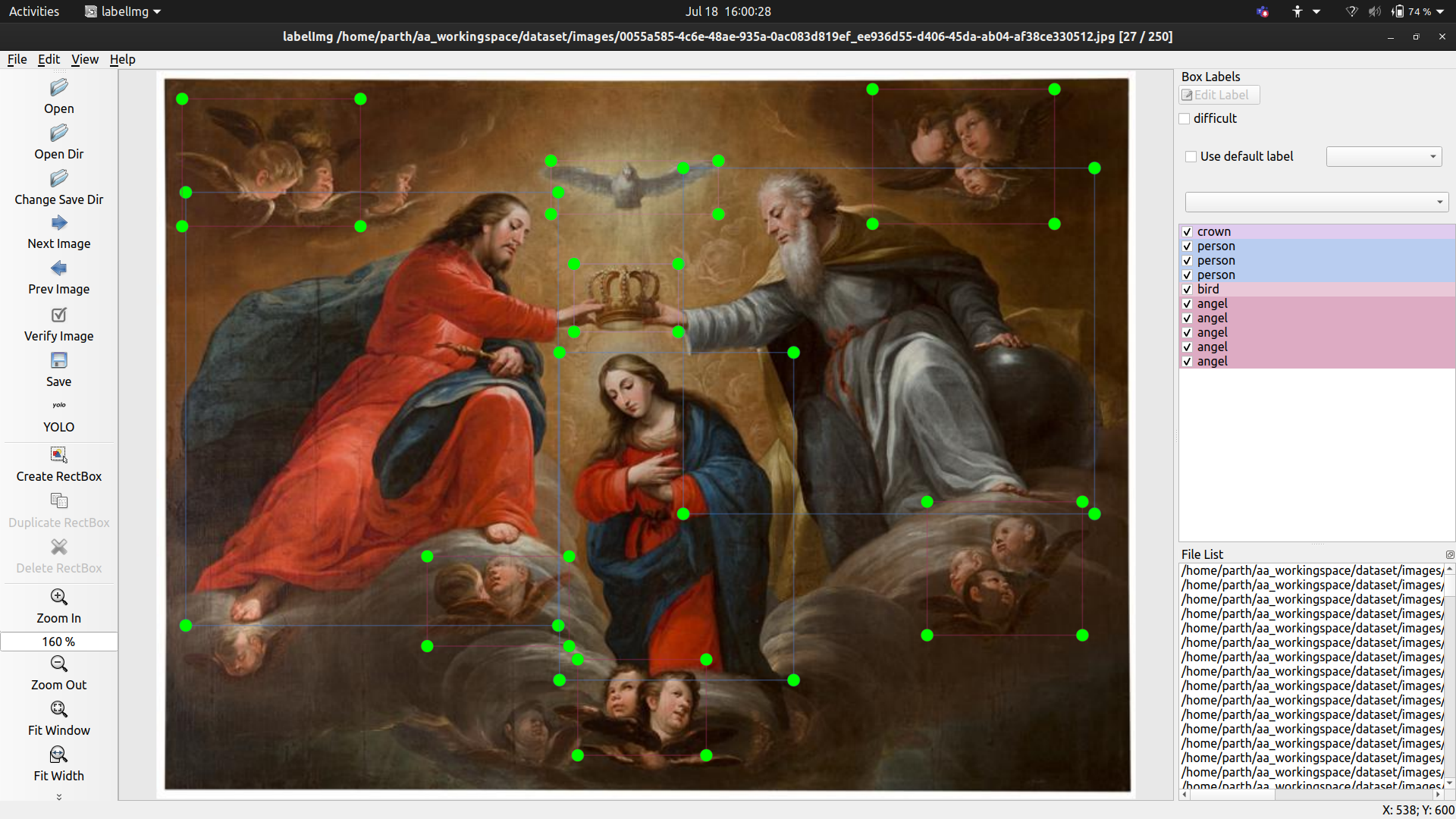
This is a Mary image with a lot going on. There are instances of Person, Crown, Bird, Angels.
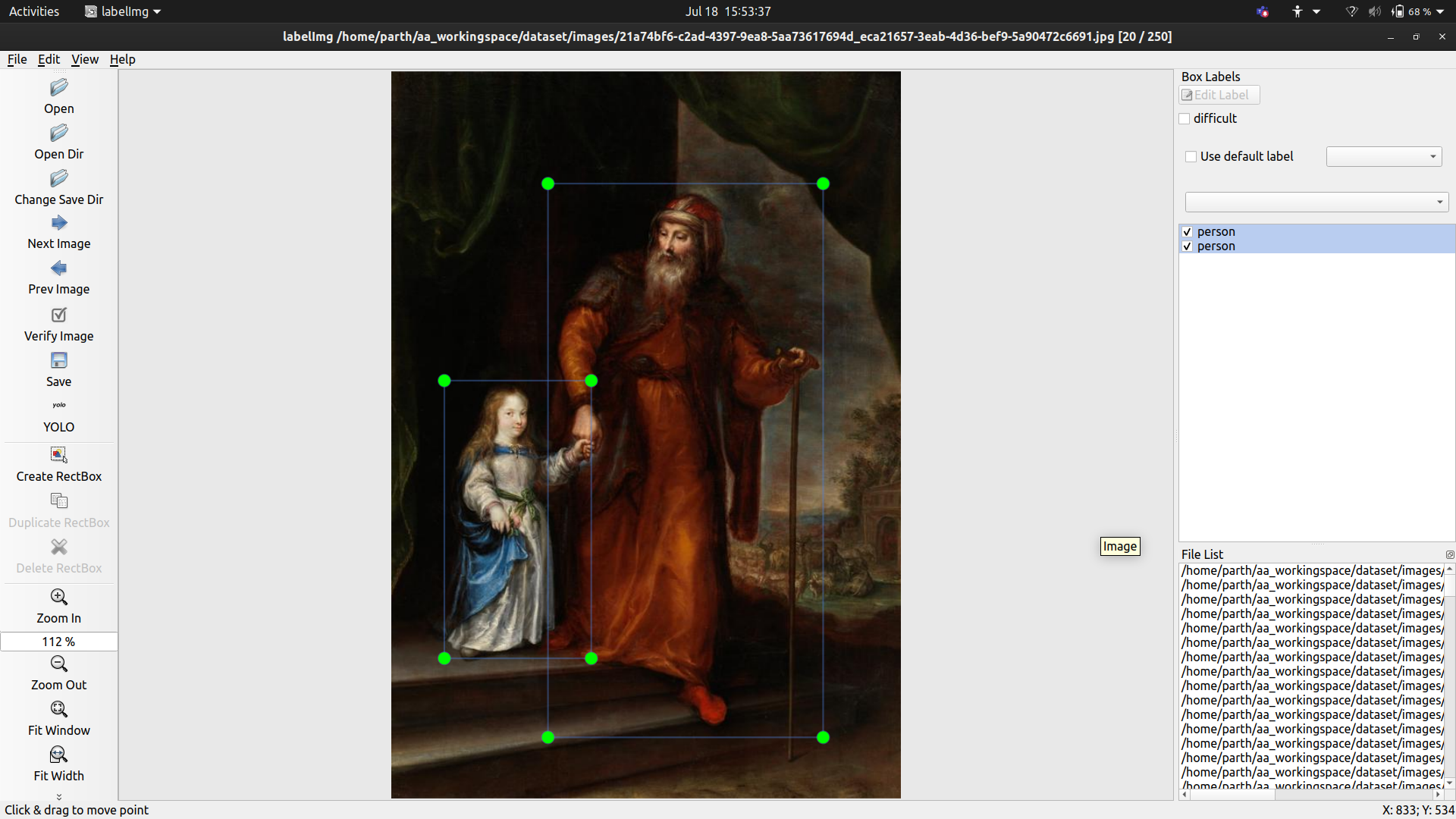
In this mary is represented as a kid with a person, who I can only assume to be Joachim because of age difference and their potrayal, this would deceive our classifier which is used to seeing a baby and a lady in a picture.
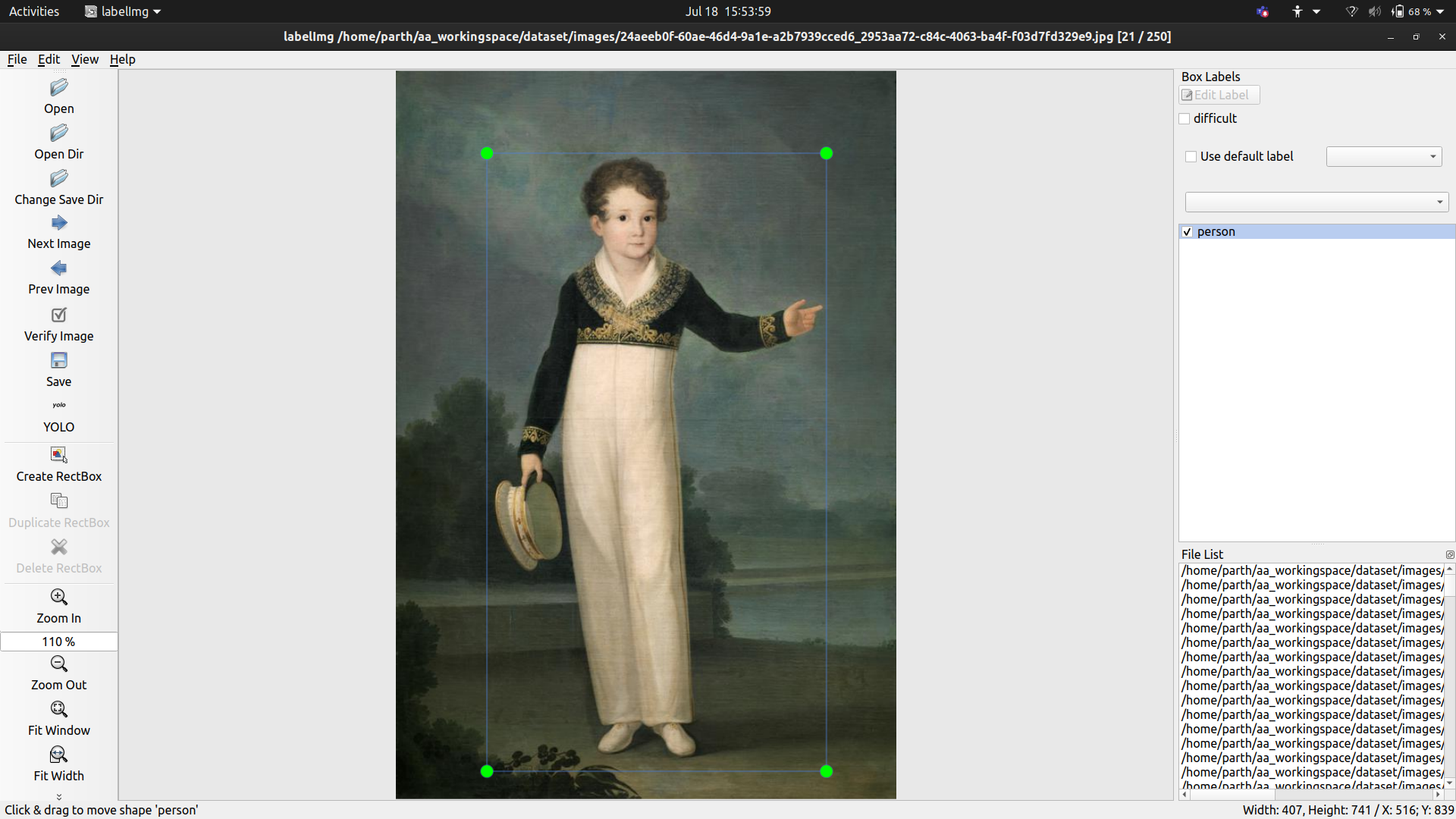
In this Mary is represented as a kid, however I’m not sure why this style has been applied
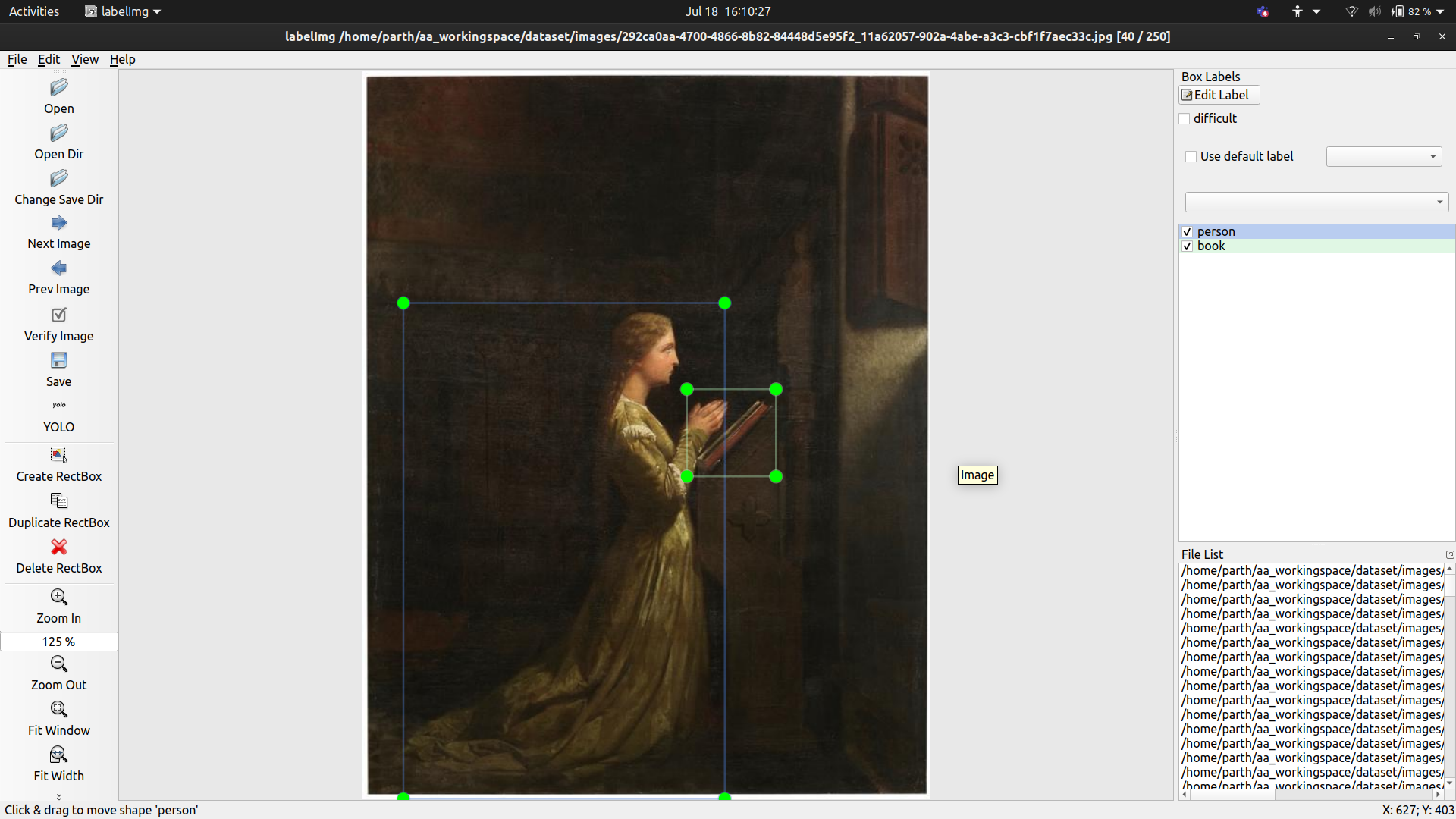
Another potrayal of slightly youunger Mary, praying in front of a book. Again, it does not contain the repetitive features that we observe and could fool anyone.
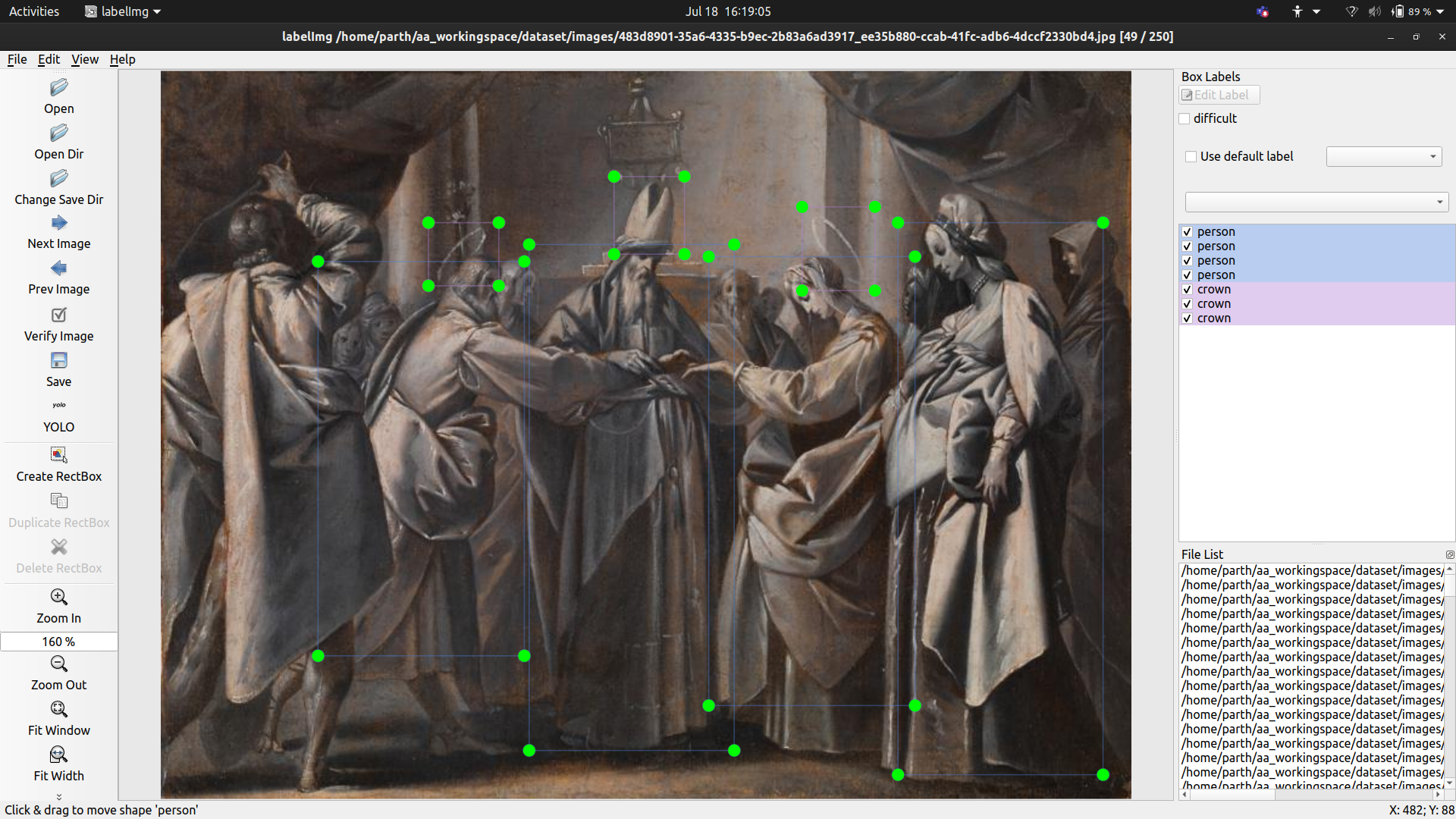
Marriage of Mary and Joseph. This one in particular is also different in style to the others.
Tuesday
Completed tagging approximately 250 images with twelve classes.
- baby
- person
- angel
- book
- jar
- crown
- bird
- crescent
- flowers
- crucifixion
- pear
- skull
The dataset is available here. My hope for this dataset is that in the future it might be possible extend this for other symbols or maybe set-up semi-supervised learning methods to tag more images.
However, the distribution is not even. In fact, it is highly disproportionate towards classes like person and baby. Currently, training YOLOv6 to observe results.
Results:




Some good outputs:



Some bad observations where the model failed:


These show the deficiencies of the if artwork of different styles is passed, however one might consider that these artworks might even confuse an untrained eye as the first one is extremely dark and the second one is monochrome.
Wednesday
- Compiling the modules together
- Cleaning of texts to produce better embeddings
Methods used to clean texts:
- In texts many titles of Mary are used, which are not useful to us, to replace them with Mary.
- Similarly, some other words have been changed with their synonyms to make embeddings more uniforms.
- The methods mentioned above have helped the embeddings because the texts I am using right now are fewer in number. I think if a huge corpus of good and less noisy texts are found, these techniques would not be required.
- Removing punctuations using the string library.
- Removing common words in the dictionary using stop words from the nltk library.
- Stemming. See this link. I am currently using Lancaster stemming.
Current results: Words like baby, crown, crucifix, book are close enough to mary to be considered as related to her. One example which is not in favor of this method is that pear which closely associated with Mary is further away. I think this problem can be solved by increasing the size of the training examples.
Now that we have all three models that I planned for the pipeline defined after the mentor meet. i can start compiling them together and observe results.
Our initial classifier was giving us around a 76 percent accuracy on the entire dataset of 42000 images. My hope is that this pipeline can increase that accuracy, even if by a few percentage.
Thursday
- Putting the pipeline together.
- Divided it into 3 stages - The initial classifier, YOLOv6, and then the word embeddings.
The demo code can be found here
Bash script for the pipeline
#!/bin/bash
source venv/bin/activate
python3 stage1.py
echo stage 1 done
cd YOLOv6
python tools/infer.py --yaml data/dataset.yaml --img-size 416 --weights runs/train/exp1/weights/best_ckpt.pt --source ../data/images
mkdir ../out2
cp -r runs/inference/exp/ ../out2/
cd ..
echo stage 2 done
python3 stage3.py
echo task completed
Results - I took 10 semi-random(random however slightly monitored so that I could observe few different type of inputs) images from the dataset.
After passing through the initial classifier i.e stage 1 of the pipeline, I was getting 30 percent accuracy. You can see the detailed results here.
Then passing through the stage 2 and stage 3 of the pipeline that increased to 70 percent. Detailed results.
One thing to note here is, at the end of the day it is only 10 examples and we do not know how well they will generalize. I will try to pass the entire dataset through the pipeline tomorrow.
Friday
Running the entire pipeline on around 2000 images. I wrote a python script to observe the difference in score after stage 1 and stage 3.
After stage 1, I observed a score of 50 percent(which is less than what I expected and observed before), however after passing through the entire pipeline it increased to more than 80 percent. These results were way better than I expected, so I need to check them more in detail and see if stage 1 is underperforming or stage 2 and 3 are overperforming.
Mentor meeting
- I showed them a demo of the pipeline and discussed outputs and what modules required more finetuning.
- Discussed on what to do next.
- I suggested to work on the singularity next and push this to the Case Western HPC because singularities are new to me and I do not know how much time I will need to learn about them. So it would be better if I first try to make a singularity on my own and see how much time I need, then going forward I can decide how much time I can dedicate to separate modules.
Saturday
- Presentation for meeting on monday
- Progress check with the timeline decided in my initial proposal
Progress Check
Original Gantt chart
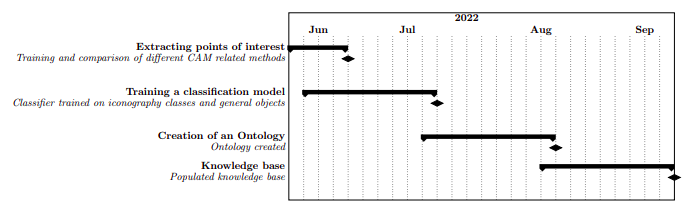
According to the timeline I proposed in the beginning, by now I should have worked in CAM methods and a general-purpose object classifier, which I have. Links to the work
- Grad-CAM training module
- Extracting objects module
- EfficientNet training notebook for general-object classifier
However, these results were not impressive enough and might not even scale very well going forward. I had to change my plan.
I tried focussing only on mother mary and seeing how well I could build a system that could just say if an image contained mother mary or not. I trained a basic classifier for this task - notebook.
An interesting thought given by Tiago was to try to utilise the vast library of texts and create a sort of embedding space for words. So I decided to explore that space.
I collected data only from two sources, https://en.wikipedia.org/wiki/Titles_of_Mary#Descriptive_titles_of_Mary_related_to_visual_arts and https://www.christianiconography.info/maryPortraits.html. Very little data, but high quality data. See data and data. Passed this data through cleaning pipeline and create embeddings. You can find the code here.
After this, I had to train the YOLO part of the pipeline. In order to not be redundant, I recommend through Blog Report 7 in which I had described the process thoroughly, right from the dataset curation to the training.
What I plan to do next? I have decided a list of targets I think are possible and listed them in the order of priority.
- Singularity - Contain my current pipeline in singularity. I think it would take 1 week to learn about singularity and code it, but I am not sure about this and that is why I want to finish this first so that I am comfortable with the concept and I know how much time it takes which wouldn’t cause me to rush my project in the end.
- Create better embeddings - Finding better data and putting better cleaning techniques should give better embeddings eventually helping the pipeline.
- Tagging more data for YOLO and getting better labels. For example, on call Mark explained how a lamb is also a common symbol in christian iconography which I was not aware about, so I must’ve missed some stuff during initial dataset curation, which can be helpful to the pipeline.
- Finally, adding a module to pipeline that can help to classify which era does a mary painting belong to.
Blog Report 8
Goals-
- Learn about Singularity
- Deploy Émile Mâle singularity on CASE HPC
Monday
- Finished presentation for mentor meet. Link
- Learning about singularities
- https://docs.sylabs.io/guides/2.6/user-guide/build_a_container.html
- CASE HPC singularity site
- Youtube tutorial
- Basics
- SLURM Array jobs, not really relevant but I found this useful while learning about HPC.
Tuesday
Saw some videos made by Harshit Mohan Kumar on Singularity. You can check their github repo for the docker code. I found those helpful.
Wednesday
Started coding dockerfile on my github repo and using github actions making the container.
I faced some issue installing pycocotools which is used in YOLOv6 module. Removing the dependency helped me build the container.
Thursday
Singularity deployed!!
My code for the Dockerfile
FROM ubuntu:20.04
RUN apt-get update
RUN apt-get install --assume-yes --no-install-recommends --quiet \
python3 \
python3-pip \
ffmpeg
RUN pip3 install --no-cache --upgrade pip setuptools
WORKDIR /EmileMale
ADD ./EmileMaleV1/ .
RUN ls -a
RUN pip3 install -r requirements.txt
Building on the ubuntu 20.04 image, I first copy the contents of repository and install the relevant modules required to the docker image using pip.
My code for the shell script
#!/bin/bash
module load singularity/3.8.1
mkdir emilemale
cd emilemale
rsync -az pas193@rider.case.edu:/mnt/rds/redhen/gallina/home/pas193/EmileMaleV1/ .
rsync -az pas193@rider.case.edu:/mnt/rds/redhen/gallina/home/pas193/singularity/emilemalev1.sif .
singularity exec -e -B /mnt/rds/redhen/gallina/home/pas193/test/emilemale emilemalev1.sif ./run.sh
mv out1.csv ../.
mv out2/ ../out2
mv final.csv ../
cd ..
rm -rf emilmale
First I load the singularity module to the HPC. Then I make the folder for the pipeline where I copy the environment using singularity and all the other python scripts and model weights required. Followed by singularity exec command. Something to note is that I had to bind the singularity to the current path and then execute the run.sh script which I have explained before in my blog(it is the executor script for the pipeline). Finally I move the output from all three stages back to the original repository and delete all the files I rsync-ed.
Friday
- Made some small changes to the pipeline so that it can function as an end-to-end prediction pipeline without the requirement for labelled data. Changes - changed the dataloader for ResNet, output format for stage 1 and stage 3. Code for version 2 of the pipeline.
- Reading of The Gothic Image Religious Art in France of the Thirteenth Century Émile Mâle.
Saturday
Continued reading The Gothic Image Religious Art in France of the Thirteenth Century Émile Mâle.
Blog Report 9
Goals-
- Use more text to create better word embeddings.
- Label more data for YOLO and re-train YOLO.
Monday
Initial reading of Émile Mâle has given me the following ideas for pre-processing.
- Currently, I am only creating coordinates for a single word like mary or crown but in text group of words are also used for example, “Our Mother” for mary, “Saint John”, “New testament”. Capturing these group of words will be useful.
- Words like “dove” should be grouped to bird for our use-case.
- Since there are many divisions in paintings of Mother mary as well depicting various phases of her life, I can try to include more text on them so learn their embeddings.
Tuesday
- Start collecting more data from Émile Mâle.
Sentences like “the Virgin must wear a veil, symbol of virginity, and the Jews are known by their cone-shaped caps.” and If he would represent the Crucifixion he must place the Virgin and the lancebearer to the right of the Cross, St. John and the man with the sponge to the left.” Why am I doing this? Collecting more of these sentences will lead to more meaningful embeddings. How am I doing this? It is a time-taking process because Emile Male has a lot of sentences with the word “virgin” but not all of them are relevant, for example, a few of these occurances are for the Wise and Foolish Virgins which is not something that I am focusing to solve right now. So, I need to go through all the sentences and hand-pick the ones which I feel are relevant.
Wednesday
-
Collecting data from Émile Mâle and artwork descriptions from the dataset curated by Rishab
-
As per discussion with Prof. Mark Turner, I added lamb to the predefined classes for YOLO. Examples:
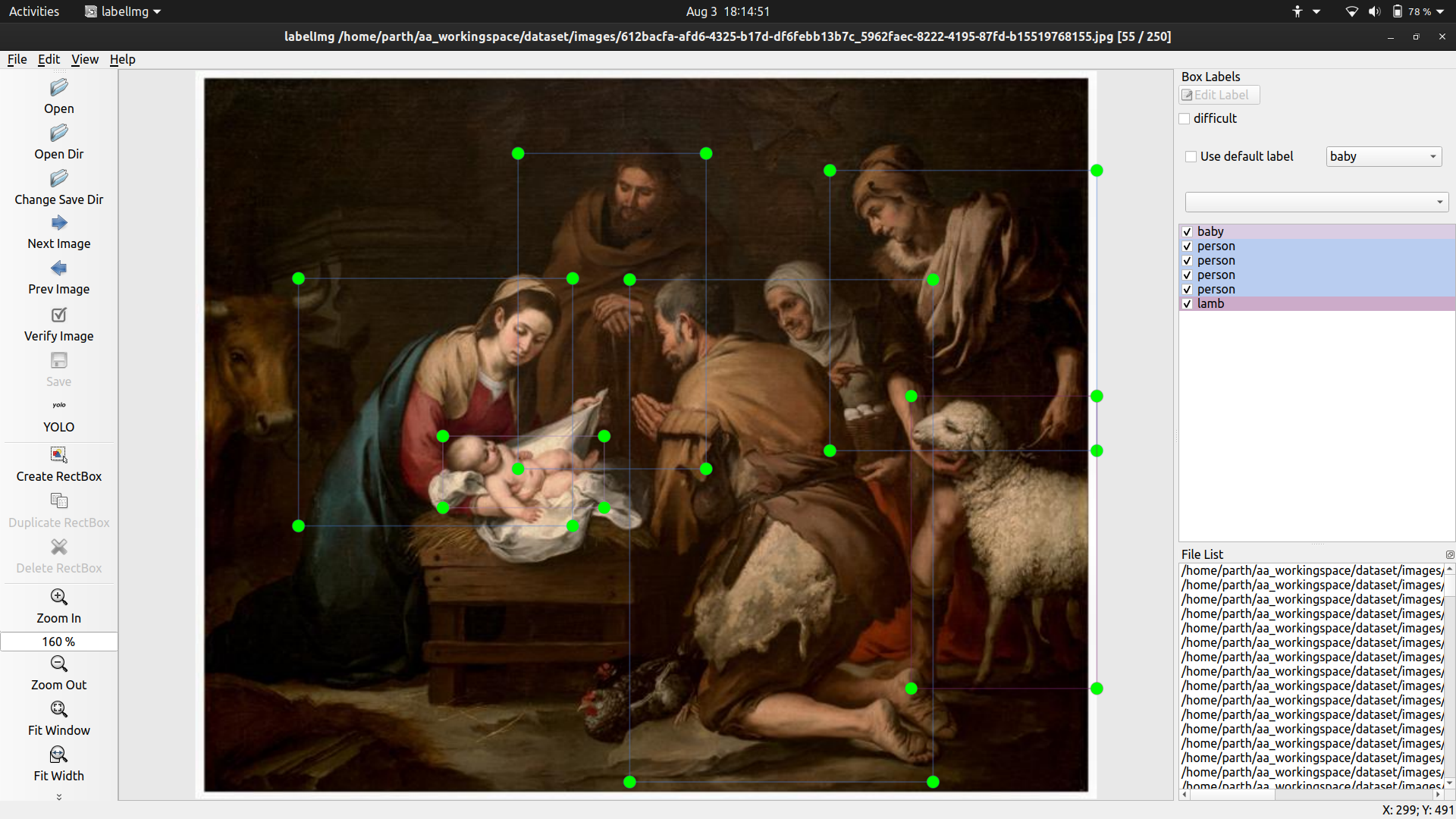
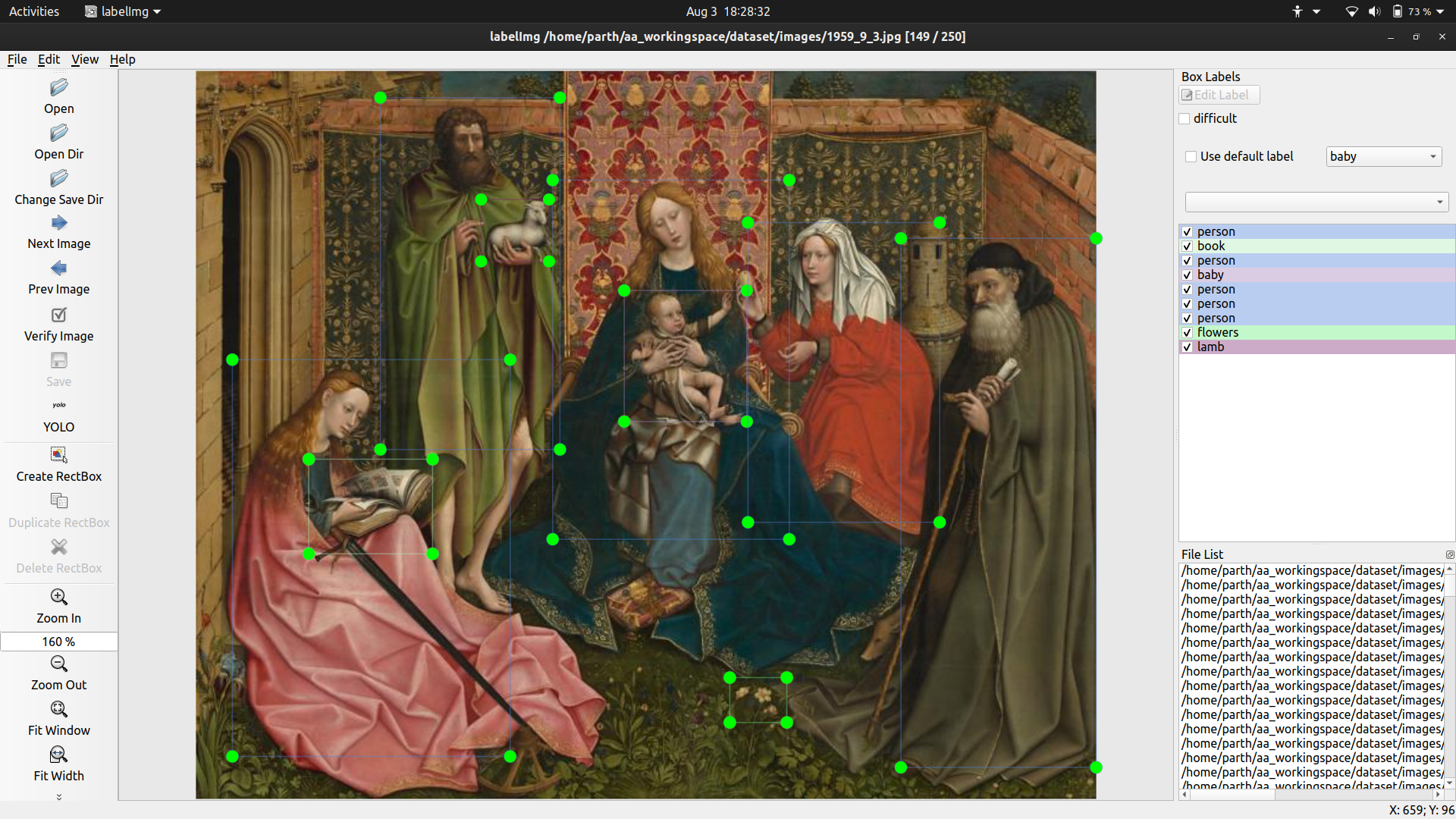
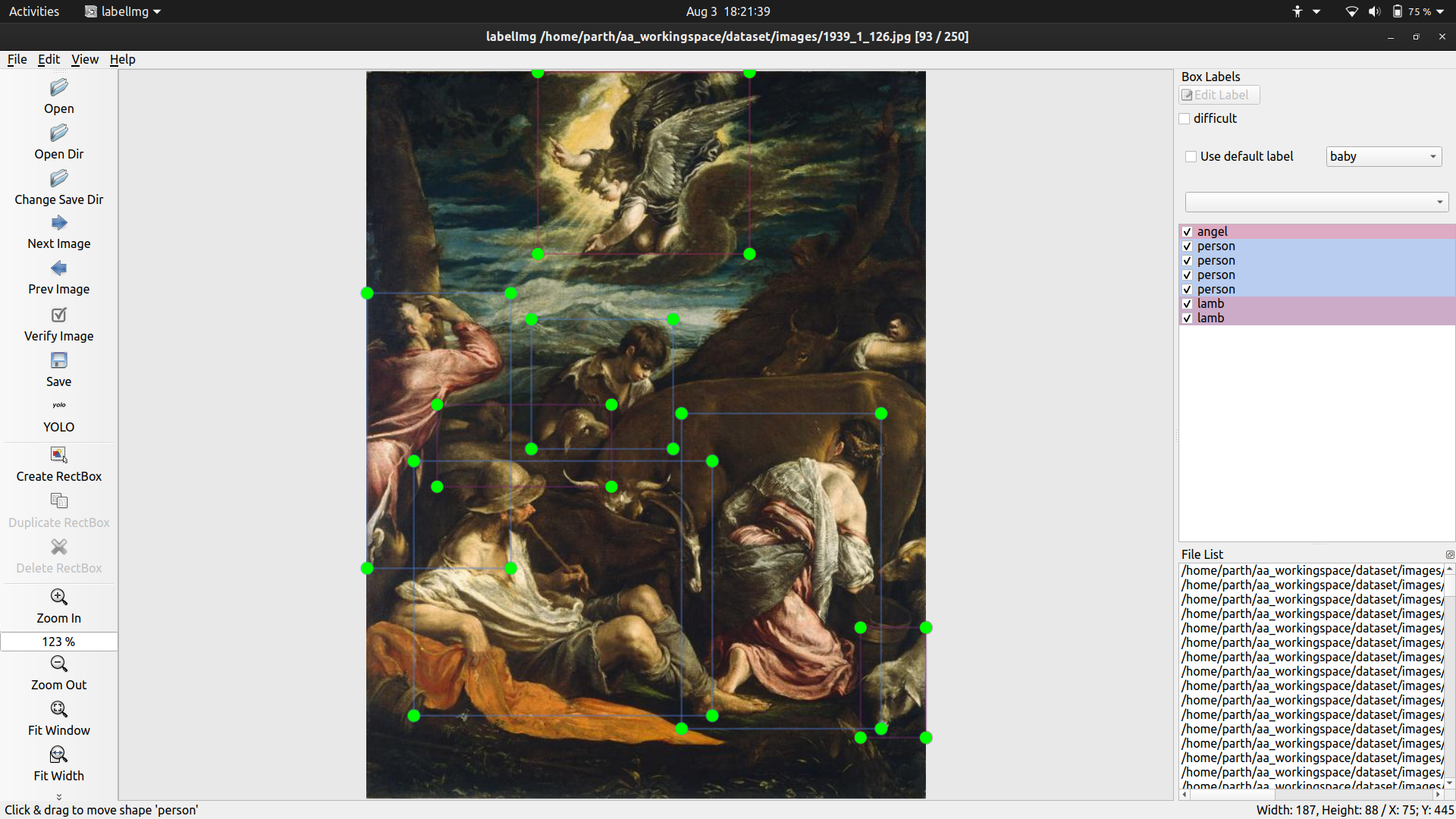
Thursday
- Tagged 100 more images for YOLO. Notable examples
This artwork is Mary at the cross. We know that there is Christ in this picture because of the writing at the top of the cross. This is good way to identify Christ and should be kept in mind for future use cases.

Another common theme of artwork is Anunciation of Mary. In these, there is a angel from heaven who comes down to Mary while she is prayer to tell her that she is going to be pregnant by God. Another thing I noticed was that in a lot of these, there are white flowers, book and a flying bird(always at a distance). These features can be used to cause the distinction.
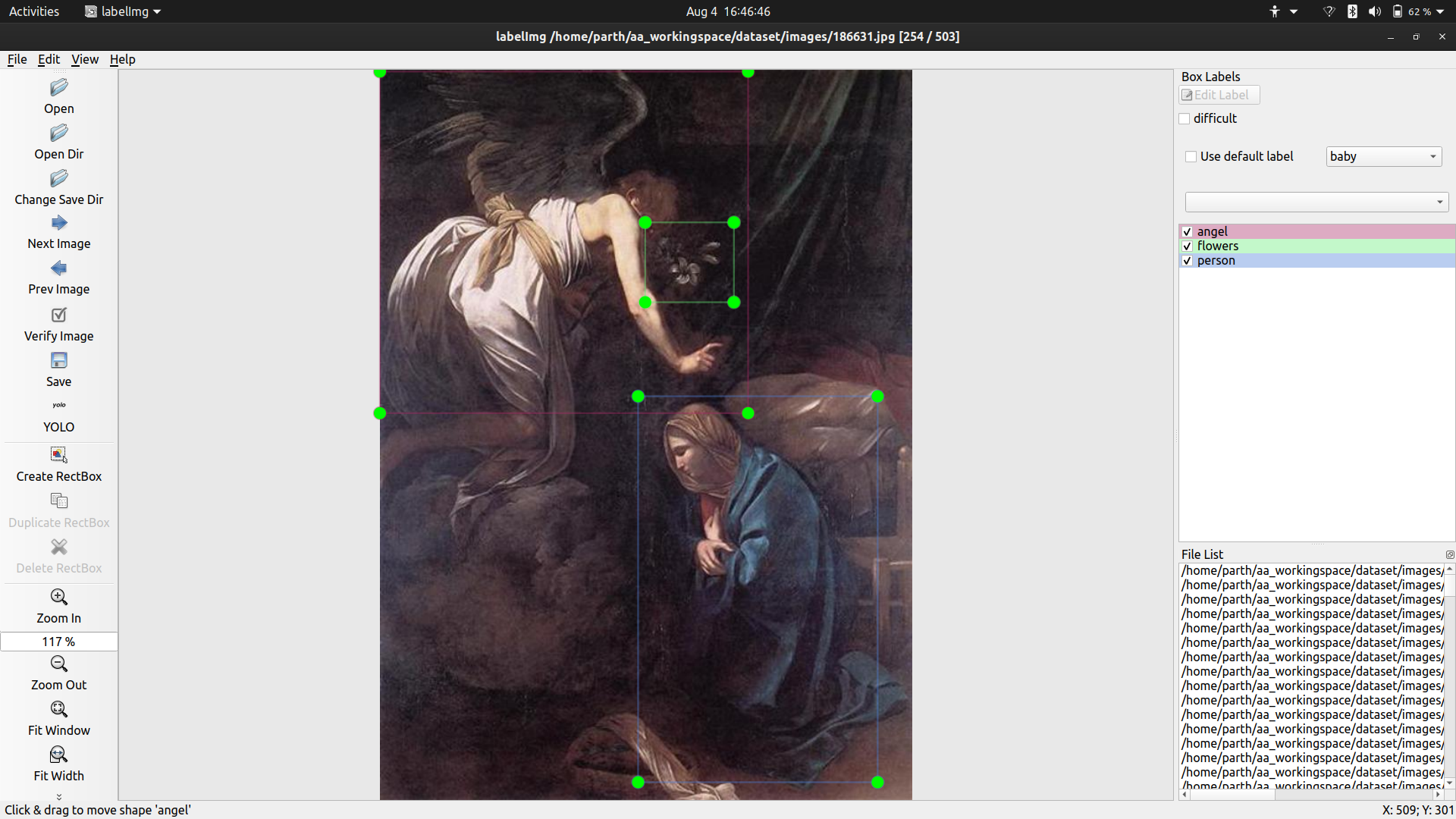
Coronation of Mary, the event in which Mary is crowned as the queen of heaven.
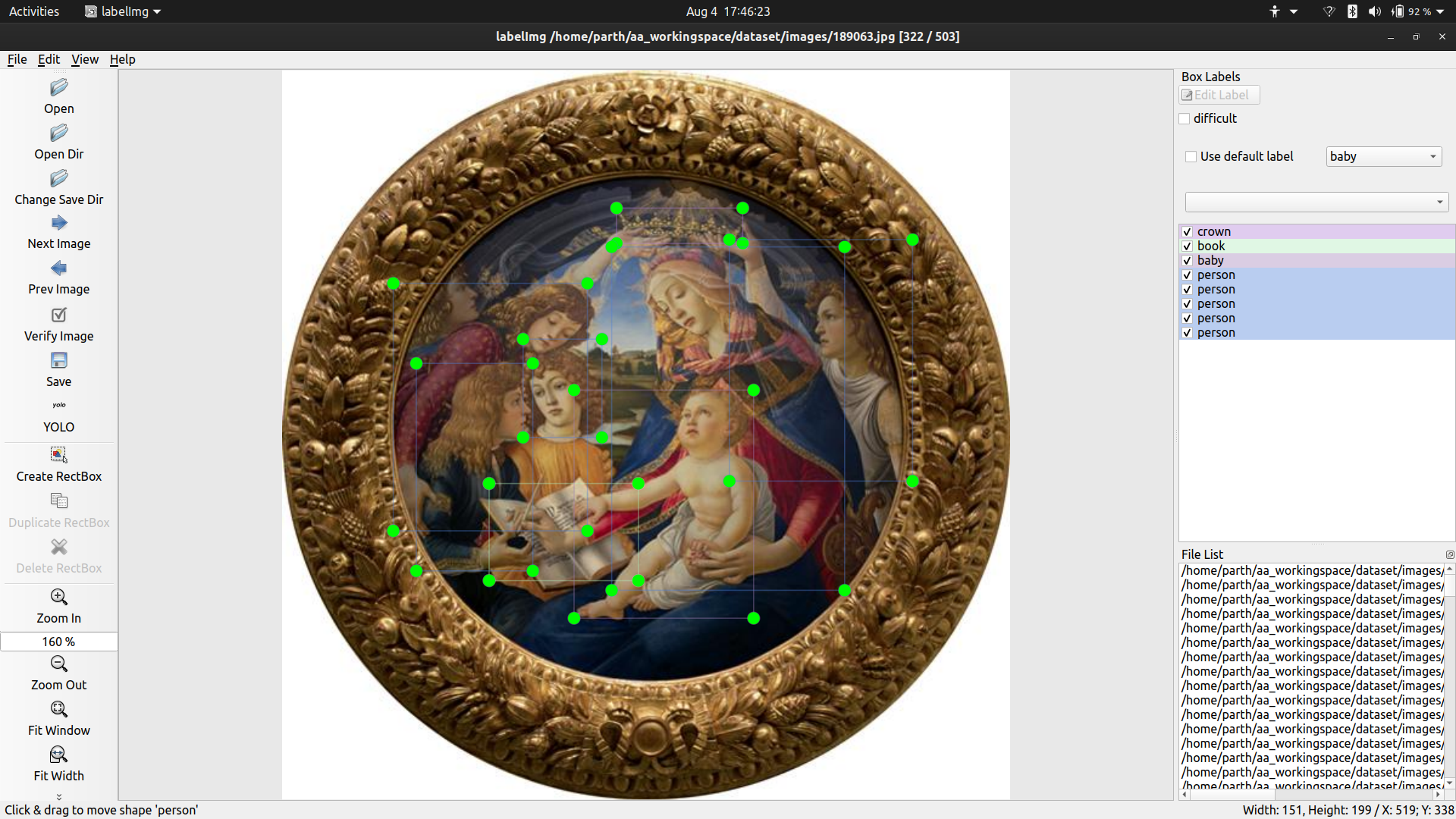
- Training word2vec on the new dataset to observe results. Tomorrow I will write some more code to the preprocessing pipeline.
Results - Closest words to Mary
[['mary', 0], ['angel', 0.0682279221558858], ['on', 0.08013687422711313], ['art', 0.08430970302191221], ['christ', 0.08823141795603906], ['baby', 0.09108800980423859],
As you can see, adding more relevant data is giving more intuitive results.
Friday
- Tagged more 100 images on Mother Mary.
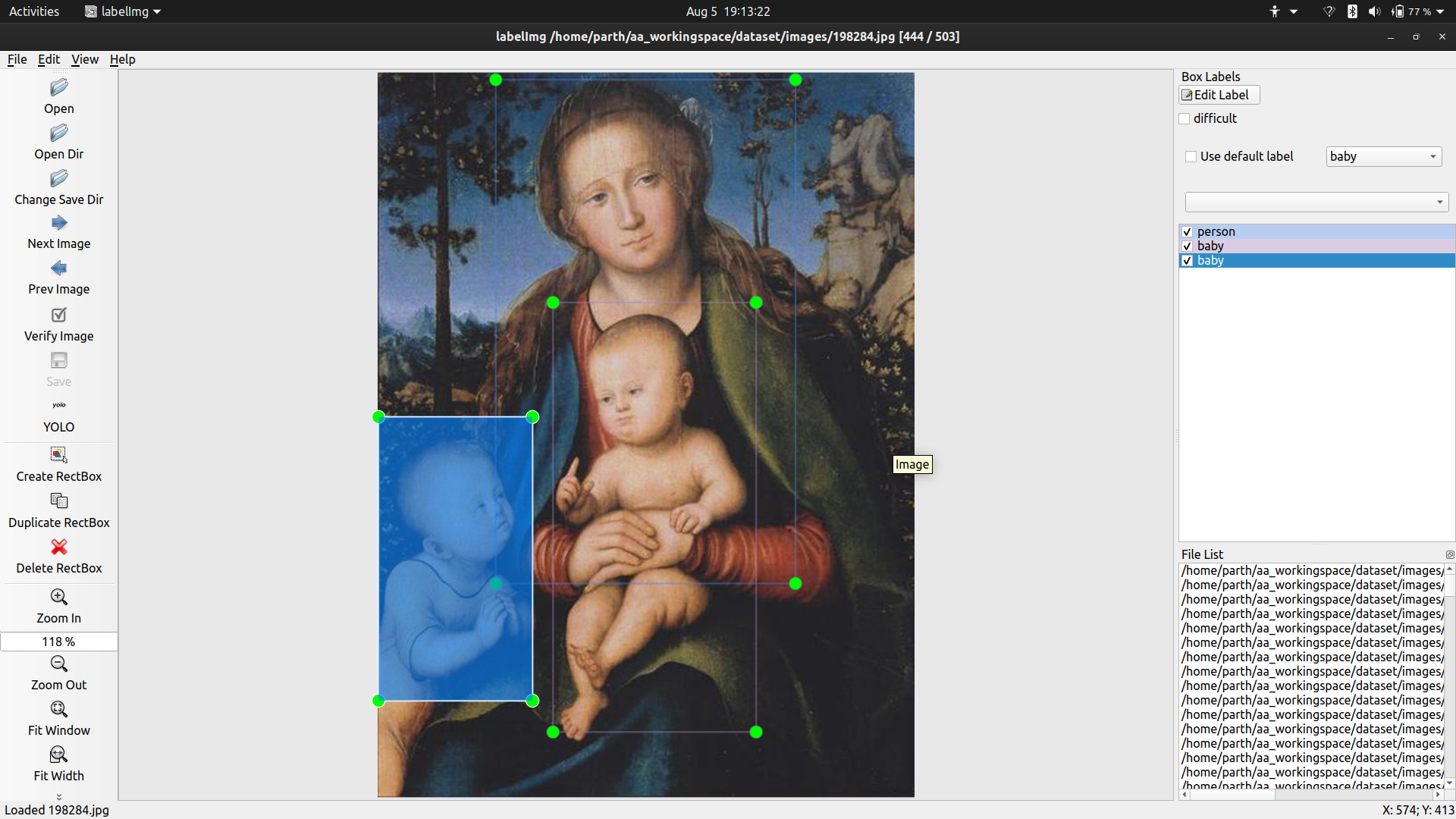
One of the common types of art is baby christ with mother mary and john the baptist as a child like the one here.
There are some pieces of art which are just tough to comprehend. I do not expect the system to work well for these.
- Adding some preprocessing code for word2vec.
I noticed that using a lemmatizer before replacing the synonyms had adverse effect on the embeddings, so I decided to shift the lemmatizer after the replacing.
I also need to work on words which occur as pair. For example, St. John or Thirteenth-century as these words only make sense when they occur together otherwise they mean something else completely.
Blog Report 10
Goals -
- Re-train YOLO
- Complete documentation for version 1 and 2 of the pipeline
- Read up on different representations of Mother Mary
- Try to figure out if I can utilise openCV for gesture detection in art (see work by Sergiy Turchyn)
Monday
- Re-trained YOLO on the dataset which can be found here.
Results -
Good results -


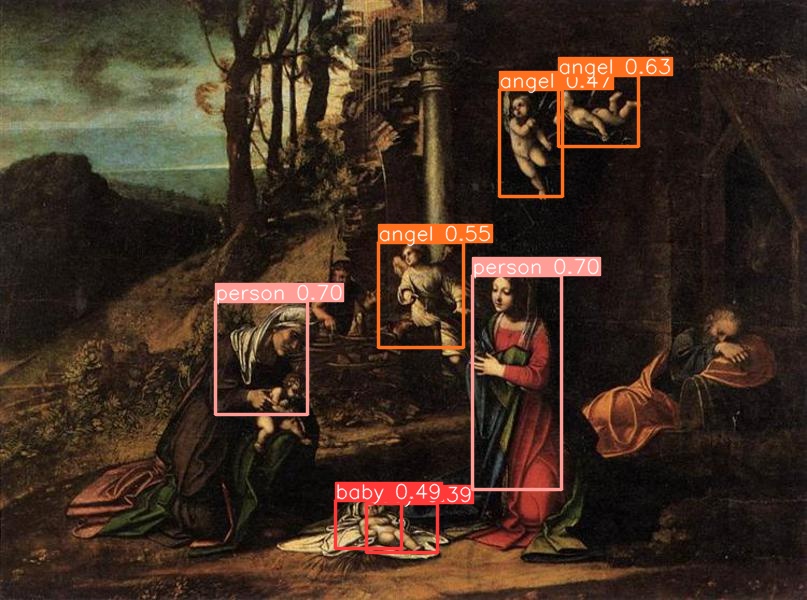


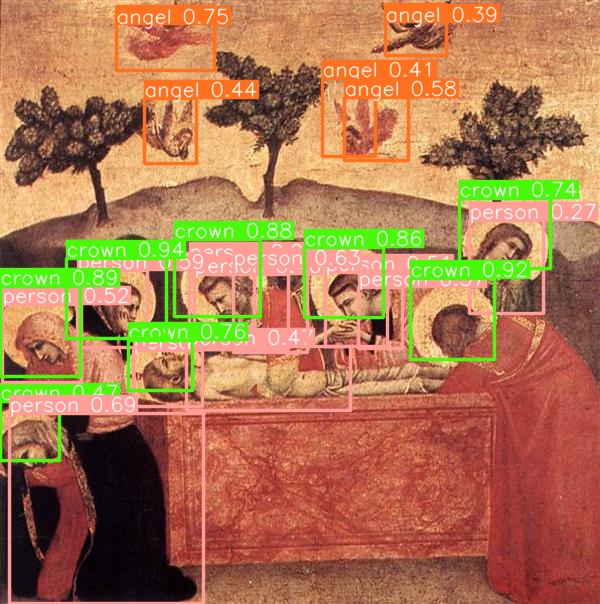



Bad results


Different ways in which Mary is depicted in Christian Iconography
- Birth of Virgin Mary/Nativity of the blessed Virgin Mary
- Marriage of the virgin
- The annunciation of the Blessed Virgin
- Nativity of Jesus
- Adoration of Magi
- Coronation of the Virgin
- Assumption of the Virgin
- Death of the Virgin
Tuesday and Wednesday
Completed documentation for Version 1 and Version 2 of the Émile Mâle pipeline.
Features particular to each type-
- Birth of Virgin Mary/Nativity of the blessed Virgin Mary
It is very similar to birth of Christ. Only difference I find between them is that Christ was born in a stable whereas Mary was born in a house near a temple in Jerusalem. I think I can leverage this to differentiate between them.

- Marriage of the virgin
Marriage of the virgin depicts a ring ceremony between Mary and Joseph performed in the presence of a minister. Mary’s hand is extended and so is Josephs’. A pose detection method might be helpful to classify among these.

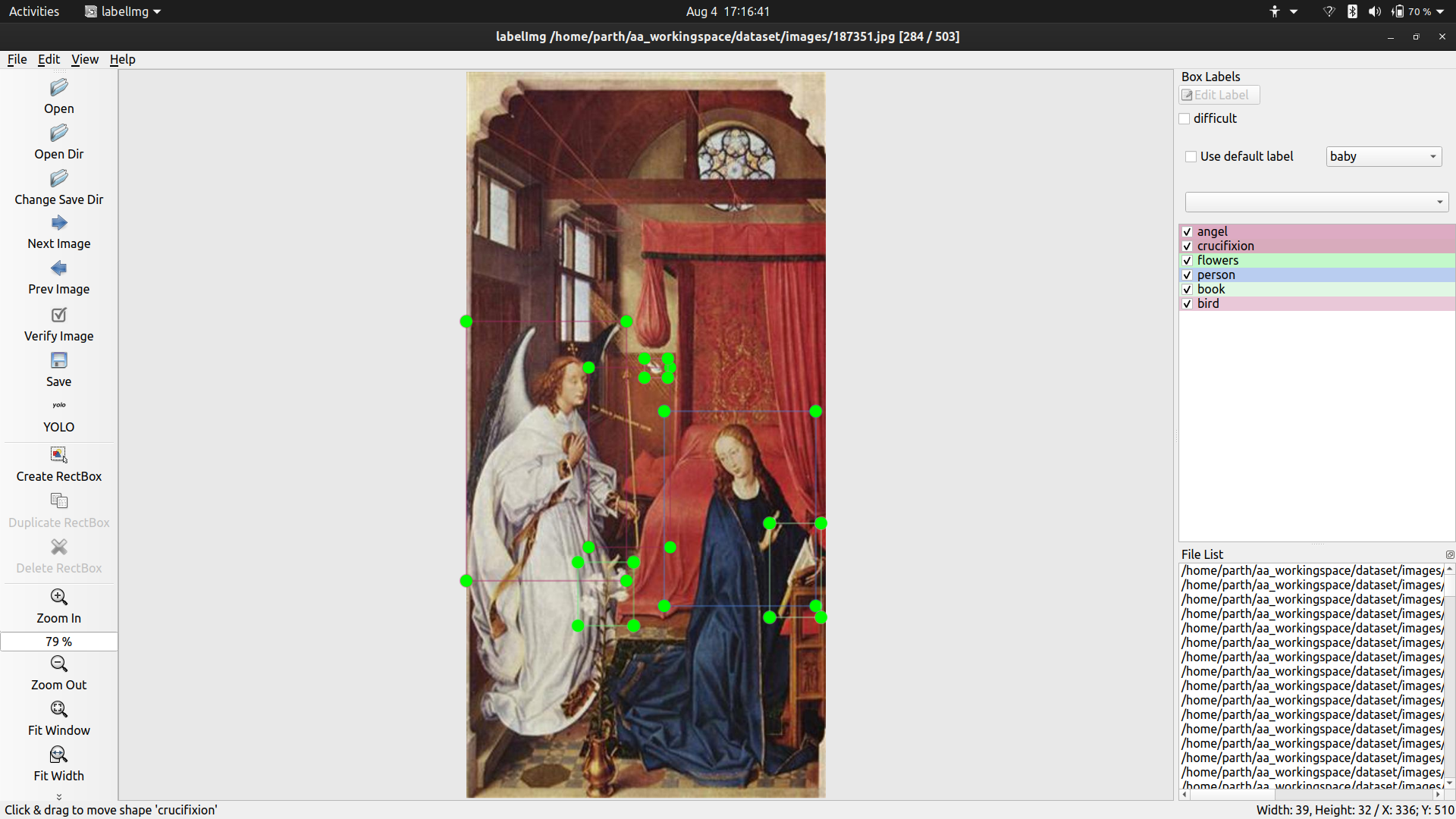
- The annunciation of the Blessed Virgin
This usually depicts the scene in which an angel comes down from heaven to tell Mary that she will conceive the child of God soon. There are usually flowers, a book, a bird far away and Mary in a prayer position to identify these paintings.

- Nativity of Jesus
It is very similar to birth of Virgin. Only difference I find between them is that Christ was born in a stable whereas Mary was born in a house near a temple in Jerusalem. I think I can leverage this to differentiate between them.

- Adoration of Magi
This depicts the scenes when the three Magi got gifts for the Child of God. Usually, one of them is on their knees with hands together in prayer position, others might be standing but are always holding gifts. These factors can be used to identify these paintings.

- Coronation of the Virgin
A very vivid event. Virgin is crowned as the Queen of heaven. Usually, two saints are crowning the Virgin in presence of angels and birds.

- Assumption of the Virgin
The virgin’s ascension to the heaven. Lifted up by angels.

- Death of the Virgin
Mary’s body lying in the center with people around her moping so some of pose approximation might help in this case.

Saturday
Experimenting with Mediapipe for pose approximation.

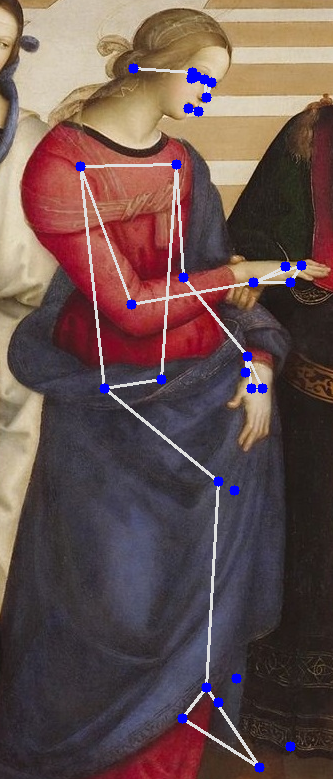
These estimations can be helpful in classifying the scene depicted in the painting.
Blog Report 11
Goals
- Version 3 of the pipeline with the new YOLO weights and embeddings and observe results
- Continue working on the gesture estimation pipeline
Monday
Working on the Version 3 of the pipeline.
Tuesday
Pushed code for EmileMaleV3.
Before further working on the gesture estimation pipeline, we need to take a step back and decide what all factors can be looked for to identify paintings:
- Birth of Virgin Mary/Nativity of the blessed Virgin Mary
Usually, shown in the picture - A baby(mary) and people around in the hotel.
- Marriage of the virgin
The two main protagonists facing each other with their extended towards each other.
- The annunciation of the Blessed Virgin
An angel, a person(mary), a book, flowers and bird far away(spirit of christ). These features are consistent in all annunciation art.
- Nativity of Jesus
Usually, shown in the picture - A baby and people around in the stable. Presence of animals can be striking feature to distinguish this.
- Adoration of Magi
Baby with the three Magi, usually one of the Magi is kneeling and all of them come bearing gifts.
- Coronation of the Virgin
Two saints crowning the queen(mary) and bird is also common. The hand position of the saints can be used.
- Assumption of the Virgin
Still unclear on what features can be used.
- Death of the Virgin
Mary lying in the middle of the scene. People around weeping or sad.
- Virgin and the child
Baby and Mother Mary. Sometimes baby has a fruit or a bird in his hand.
Wednesday and Thursday
As per above discusion, each type of image has a certain set of characteristics that can be used to identify the art. But these features can overlap so we need to assign a confidence score for each class.
Methodology I am planning to use -
-
First let’s consider all the classes I am taking right now. [‘birth_virgin’, ‘marriage’, ‘annunciation’, ‘birth_jesus’, ‘adoration’, ‘coronation’, ‘assumption’, ‘death’, ‘virgin_and_child’]
-
Define an array of zeros of the 9 for all the classes.
-
Then we consider all the labels produced by YOLO for that image. If we see a baby, we add a point to classes Birth of virgin, Birth of Jesus, Virgin with child, Adoration of Magi since these classes have a baby in them. If we see a lamb, then we add a point to Birth of jesus because he was born in a stable.
-
Apply softmax and return the most probable class.
The methodology above is not complete and I will further work on it.
Friday
Mentor meeting - Discussion on the scope of project and how to wrap it up.
Saturday
Results of the methodology mentioned above-

Prediction -
- 30.8% Virgin with child
- 11.3% Birth of Virgin
- 11.3% Birth of Jesus

Prediction -
- 59.64% Assumption of the blessed Virgin
- 8.07% Coronation
- 8.07% Death of Virgin

Prediction -
- 78.1% Annunciation
- 10.6% Coronation
- 3.9% Virgin with Child

Prediction -
- 59.49% Coronation
- 8% Death
- 8% Marriage
Blog Report 12
Goals -
- Continue working on the stage 4 of the pipeline
Monday
Creating a data augmentation pipeline in order to re-train YOLO. I have come to understand that I need my object detection model to become as accurate as possible because it forms the base of my pipeline so it makes sense to spend more time on it.
Tuesday and Wednesday
Augmented dataset - Link
Training YOLO on HPC.
Thursday
Working on pose approximation.
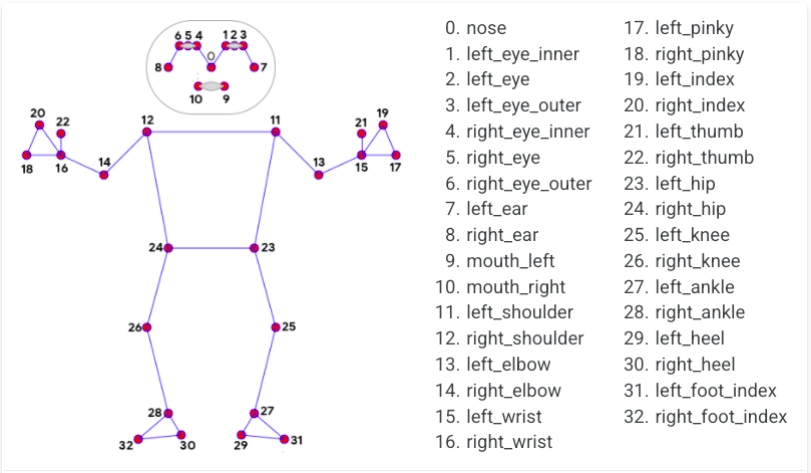
Using these keypoints generated to estimate what a person is doing. Currently, I am only considering 4 poses -
- Praying - if hands are close to each other
- Extending hand - if the avg position of hand is away from the corresponding shoulder
- Lying down - if height of nose and shoulder are similar
- Crucifix - Both left hand and right hand are extended, could be helpful for Christ
Slow progress because I was unwell.
Blog Report 13
Goals -
- Integrate pose pipeline into the scoring system
- Integrate this part into the main pipeline
- Deploy the pipeline to HPC
Monday
As we are nearing the end of the coding period, it’s time to wrap up all the loose ends complete documentation on how to use and results.
To start the week, I decided to integrate the pose code in my scoring system.
Examples of gesture -
Prayer

Extended hand

Examples not working
No gesture detected


Inference - lying down is not being detected
Tuesday
Further tests proved that lying down was indeed being recognised, however the consistency might be low.
Wednesday
Meeting
No more work done this week because of college exams.
Blog Report 14
Goals -
- Wrap up version 4
- Complete documentation
Monday
Deployed Version 4 on HPC.
Tuesday and wednesday
Completed documentation.
What to do next?
There is a lot of work that can be done on the pipeline. I have tried to make it very modular so that it is easy to add and remove modules as the pipeline becomes bigger.
Ideas -
- Trying other object recognition models, other than YOLO, and comparing their performance. The YOLO model trained is not perfect(which is a tough ask anyway) and can be improved using more data and a different model.
- The embeddings currently do not handle phrases like thirteenth century. This can be included in Word2Vec model.
- The embeddings in the current state focus only on Mother Mary, work can be done to create more generalized to include all the other saints. Try to include as much christian iconography text you can find for eg Émile Mâle - The Gothic Image_ Religious Art in France of the Thirteenth Century (Icon Editions Series) (1972)
- Add more “stories” of Mother Mary in the last module that I have worked on.
- Add more modules for other saints.